Data Structures در پایتون
بر خلاف برخی زبان های برنامه نویسی رایج دیگر که بلاک های کد در آکولاد تعریف می شوند (به ویژه زبان هایی که از گرامر زبان سی پیروی می کنند) در زبان پایتون از نویسه فاصله و جلوبردن متن برنامه برای مشخص کردن بلاک های کد استفاده می شود. به این معنی که تعدادی یکسان از نویسه فاصله در ابتدای سطرهای هر بلاک قرار می گیرند، و این تعداد در بلاک های کد درونی تر افزایش می یابد. بدین ترتیب بلاک های کد به صورت خودکار ظاهری مرتب دارند.
پایتون مدل های مختلف برنامه نویسی (از جمله شی گرا و برنامه نویسی دستوری و تابع محور) را پشتیبانی می کند و برای مشخص کردن نوع متغییرها از یک سامانه پویا استفاده می کند. این زبان از زبان های برنامه نویسی مفسر بوده و به صورت کامل یک زبان شی گرا است که در ویژگی ها با زبانهای تفسیری پرل، روبی، اسکیم، اسمال تاک و تی سی ال مشابهت دارد و از مدیریت خودکار حافظه استفاده می کند.
پایتون پروژه ای آزاد و متن باز توسعه یافته است و توسط بنیاد نرم افزار پایتون مدیریت می گردد.
پایتون قابل توسعه است:
). زمانی که واقعا درگیر شوید، می توانید مفسر پایتون را به یک برنامه نوشته شده به زبان C اتصال دهید و از آن به عنوان یک افزونه یا دستور زبان برای آن برنامه استفاده کنید. ضمنا نام این زبان برگرفته از برنامه Monty Python’s Flying Circus در BBC است و هیچ ارتباطی با خزندگان ندارد(مار پیتون). ارجاع به مستندات Monty Python skits نه تنها مجاز است ، بلکه مورد تشویق نیز واقع می شود.
حال که همه شما درباره پایتون مشتاق و هیجان زده هستید، میخواهید آن را با جزییات بیشتری امتحان کنید. از آنجایی که بهترین راه برای یادگیری یک زبان استفاده از آن است، این آموزش همزمان با خواندن، شما را دعوت به بازی با مفسر پایتون می کند.
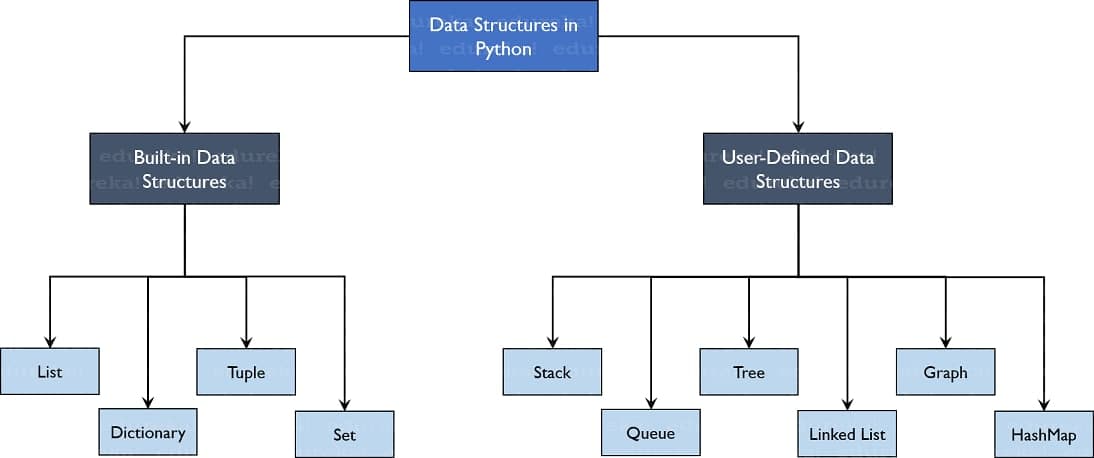
در بخش بعدی، مکانیزم استفاده از مفسر توضیح داده می شود که ممکن است اطلاعات کسل کننده ای باشد اما برای انجام مثال هایی که بعدا نشان داده می شوند ضروری است. در ادامه این آموزش، ویژگی های متنوع زبان و سیستم پایتون از طریق مثال ها معرفی می شود. از اصطلاحات ساده شروع می کنیم، سپس عبارات و انواع داده، توابع و ماژول ها، و در نهایت مفاهیم پیشرفته مانند استثناها و کلاس های تعریف شده توسط کاربر معرساختارهای داده سازه های اساسی هستند که برنامه های خود را بر اساس آنها می سازید. هر ساختار داده روش خاصی را برای سازماندهی داده ها ارائه می دهد تا بسته به مورد استفاده شما به طور موثر به آنها دسترسی داشته باشید. پایتون با مجموعه گسترده ای از ساختارهای داده در کتابخانه استاندارد خود عرضه می شود.
دوره پیشنهادی:
در پایتون، (یا به اختصار dicts) یک ساختار داده مرکزی هستند. Dict ها تعداد دلخواه شی را ذخیره می کنند که هر کدام با یک کلید منحصر به فرد شناسایی می شوند.
دفترچه تلفن یک مثال مناسب در دنیای واقعی برای اشیاء دیکشنری هستند. آنها به شما این امکان را می دهند که به سرعت اطلاعات (شماره تلفن) مرتبط با یک کلید داده شده (نام یک شخص) را بازیابی کنید. به جای اینکه مجبور باشید برای پیدا کردن شماره شخصی یک دفترچه تلفن را از جلو به عقب بخوانید، می توانید کمابیش مستقیماً به یک نام بروید و اطلاعات مرتبط را جستجو کنید.
وقتی صحبت از نحوه سازماندهی اطلاعات برای امکان جستجوی سریع می شود، این قیاس تا حدودی از بین می رود. اما ویژگی های عملکردی اساسی وجود دارد. دیکشنری ها به شما این امکان را می دهند که به سرعت اطلاعات مرتبط با یک کلید مشخص را پیدا کنید. شما با کلاس آموزش پایتون در اصفهان به راحتی می توانید دست به تولید نرم افزارهایی در حوزه آماری و اقتصادی یا مدیریتی بزنید
دیکشنری ها یکی از مهم ترین و پرکاربردترین ساختارهای داده در علوم کامپیوتر هستند. بنابراین، پایتون چگونه دیکشنری ها را مدیریت می کند؟ بیایید گشتی در پیاده سازی دیکشنری موجود در هسته پایتون و کتابخانه استاندارد پایتون داشته باشیم.
ویدیو پیشنهادی:
+ dict: دیکشنری آماده به کار شما
از آنجایی که دیکشنری ها بسیار مهم هستند، پایتون دارای یک پیاده سازی دیکشنری قوی است که مستقیماً در زبان اصلی ساخته شده است: نوع داده dict.
>>> phonebook = {
… bob: 7387,
… alice: 3719,
… jack: 7052,
… }
>>> squares = {x: x * x for x in range(6)}
>>> phonebook[alice]
3719
>>> squares
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
محدودیت هایی وجود دارد که در آن اشیاء می توانند به عنوان کلیدهای معتبر استفاده شوند.
داده های غیرقابل تغییر مانند رشته ها و اعداد، قابل هش هستند و به خوبی به عنوان کلیدهای دیکشنری کار می کنند. همچنین می توانید از اشیاء تاپل به عنوان کلیدهای دیکشنری استفاده کنید، به شرطی که خود تاپل فقط انواع قابل هش داشته باشند.
برای بیشتر موارد استفاده، پیاده سازی دیکشنری داخلی پایتون هر کاری را که نیاز دارید انجام می دهد. دیکشنری ها بسیار بهینه شده اند و زیربنای بسیاری از بخش های زبان هستند. به عنوان مثال، به صورت داخلی در دیکشنری ها ذخیره می شوند.
دیکشنری های پایتون مبتنی بر پیاده سازی جدول هش به خوبی آزمایش شده و تنظیم شده هستند که ویژگی های عملکردی را که انتظار دارید ارائه می کند: پیچیدگی زمانی O(1) برای عملیات جستجو، درج، به روز رسانی و حذف در حالت متوسط.
دلیل کمی برای عدم استفاده از اجرای استاندارد dict موجود در پایتون وجود دارد. با این حال، پیاده سازی های تخصصی دیکشنری شخص ثالث، مانند یا وجود دارد.
علاوه بر اشیاء dict ساده، کتابخانه استاندارد پایتون همچنین شامل تعدادی پیاده سازی دیکشنری تخصصی است. این دیکشنری های تخصصی همگی بر اساس کلاس دیکشنری داخلی هستند (و ویژگی های عملکردی آن را به اشتراک می گذارند) اما برخی ویژگی های راحتی اضافی را نیز شامل می شوند.
بیایید نگاهی به آنها بیندازیم.
مقاله پیشنهادی: آموزش ویدویی پایتون در آپارات
+ collections.OrderedDict: حفظ ترتیب ورود کلیدها
پایتون شامل یک زیرکلاس dict تخصصی است که ترتیب درج کلیدهای اضافه شده به آن را به خاطر می آورد: .
در حالی که نمونه های استاندارد dict ترتیب درج کلیدها را در CPython 3.6 و بالاتر حفظ می کنند، این به سادگی یک اثر جانبی اجرای CPython بود و تا قبل از Python 3.7 در مشخصات زبان تعریف نشده بود. بنابراین، اگر ترتیب کلید برای کارکرد الگوریتم شما مهم است، بهتر است با استفاده از کلاس OrderedDict این موضوع را به وضوح بیان کنید:
>>> import collections
>>> d = collections.OrderedDict(one=1, two=2, three=3)
>>> d
OrderedDict([(‘one’, 1), (‘two’, 2), (‘three’, 3)])
>>> d[four] = 4
>>> d
OrderedDict([(‘one’, 1), (‘two’, 2),
(‘three’, 3), (‘four’, 4)])
>>> d.keys()
odict_keys([‘one’, ‘two’, ‘three’, ‘four’])
تا قبل از Python 3.8، نمی توانستید با استفاده از reversed() آیتم های دیکشنری را به ترتیب معکوس تکرار کنید. فقط نمونه های OrderedDict این قابلیت را ارائه می کردند. حتی در پایتون 3.8، اشیاء dict و OrderedDict دقیقاً یکسان نیستند. نمونه های OrderedDict دارای یک متد .move_to_end() هستند که در نمونه dict ساده در دسترس نیست، و همچنین یک متد .popitem() قابل تنظیم تر از نمونه های یک dict ساده است.
مقاله پیشنهادی:
این می تواند در تایپ کردن شما صرفه جویی کند و در مقایسه با استفاده از get() یا گرفتن استثنای KeyError در دیکشنری های معمولی، اهداف شما را واضح تر کند:
>>> from collections import defaultdict
>>> dd = defaultdict(list)
>>> # Accessing a missing key creates it and
>>> # initializes it using the default factory,
>>> # i.e. list() in this example:
>>> dd[dogs].append(Rufus)
>>> dd[dogs].append(Kathrin)
>>> dd[dogs].append(Mr Sniffles)
>>> dd[dogs]
[‘Rufus’, ‘Kathrin’, ‘Mr Sniffles’]
چندین دیکشنری را در یک واحد گروه بندی می کند. جستجوگرها بخش های زیرین را یکی یکی جستجو می کنند تا زمانی که یک کلید پیدا شود. درج ها، به روزرسانی ها و حذف ها فقط بر اولین بخش اضافه شده به زنجیره تأثیر می گذارند:
>>> from collections import ChainMap
>>> dict1 = {one: 1, two: 2}
>>> dict2 = {three: 3, four: 4}
>>> chain = ChainMap(dict1, dict2)
>>> chain
ChainMap({‘one’: 1, ‘two’: 2}, {‘three’: 3, ‘four’: 4})
>>> # ChainMap searches each collection in the chain
>>> # from left to right until it finds the key (or fails):
>>> chain[three]
3
>>> chain[one]
1
>>> chain[missing]
Traceback (most recent call last):
File , line 1, in
KeyError: ‘missing’
مقاله پیشنهادی:
>>> from types import MappingProxyType
>>> writable = {one: 1, two: 2}
>>> read_only = MappingProxyType(writable)
>>> # The proxy is read-only:
>>> read_only[one]
1
>>> read_only[one] = 23
Traceback (most recent call last):
File , line 1, in
TypeError: ‘mappingproxy’ object does not support item assignment
>>> # Updates to the original are reflected in the proxy:
>>> writable[one] = 42
>>> read_only
mappingproxy({‘one’: 42, ‘two’: 2})
+ نتیجه گیری: دیکشنری ها در پایتون
تمام پیاده سازی های دیکشنری پایتون که در این آموزش فهرست شده اند، پیاده سازی های معتبری هستند که در کتابخانه استاندارد پایتون ساخته شده اند.
توصیه می کنم تنها در صورتی از یکی از دیگر انواع داده های فهرست شده در اینجا استفاده کنید که الزامات خاصی دارید که فراتر از آنچه توسط dict ارائه شده است.
همه پیاده سازی ها گزینه های معتبری هستند، اما اگر کد شما در بیشتر مواقع به دیکشنری های استاندارد پایتون متکی باشد، واضح تر و راحت تر نگهداری می شود.
مقاله پیشنهادی:
آرایه یک ساختار داده بنیادی است که در اکثر زبان های برنامه نویسی موجود است و طیف وسیعی از کاربردها در الگوریتم های مختلف دارد.
در این بخش، به پیاده سازی آرایه ها در پایتون نگاهی می اندازید که فقط از ویژگی های زبان اصلی یا عملکرد موجود در کتابخانه استاندارد پایتون استفاده می کنند. شما نقاط قوت و ضعف هر رویکرد را خواهید دید تا بتوانید تصمیم بگیرید که کدام پیاده سازی برای مورد استفاده شما مناسب است.
اما قبل از اینکه وارد بحث شویم، ابتدا برخی از اصول اولیه را پوشش می دهیم. آرایه ها چگونه کار می کنند و چه کاربردی دارند؟ آرایه ها از رکوردهای داده با اندازه ثابت تشکیل شده اند که به هر عنصر اجازه می دهد تا بر اساس ایندکس خود به طور مؤثری قرار گیرد:
از آنجایی که آرایه ها اطلاعات را در بلوک های مجاور حافظه ذخیره می کنند، به عنوان ساختارهای داده پیوسته در نظر گرفته می شوند (به عنوان مثال، برخلاف ساختارهای داده مرتبط مانند لیست های پیوندی).
یک قیاس در دنیای واقعی برای ساختار داده آرایه یک پارکینگ است. شما می توانید به پارکینگ به عنوان یک کل نگاه کنید و آن را به عنوان یک شی واحد در نظر بگیرید، اما در داخل محوطه پارکینگ هایی وجود دارد که با یک عدد منحصر به فرد نمایه شده اند. مکان های پارکینگ کانتینری برای وسایل نقلیه هستند – هر مکان پارک می تواند خالی باشد یا ماشین، موتور سیکلت یا وسیله نقلیه دیگری روی آن پارک شده باشد.
اما همه پارکینگ ها یکسان نیستند. برخی از پارکینگ ها ممکن است فقط به یک نوع وسیله نقلیه محدود شوند. به عنوان مثال، یک پارکینگ موتور اجازه نمی دهد دوچرخه در آن پارک شود. یک پارکینگ محدود مربوط به یک ساختار داده آرایه تایپ شده است که فقط به عناصری اجازه می دهد که نوع داده مشابهی در آنها ذخیره شده باشد.
از نظر عملکرد، جستجوی یک عنصر موجود در یک آرایه با توجه به index عنصر بسیار سریع است. اجرای آرایه مناسب زمان دسترسی O(1) ثابت را برای این مورد تضمین می کند.
پایتون شامل چندین ساختار داده آرایه مانند در کتابخانه استاندارد خود است که هر کدام دارای ویژگی های کمی متفاوت هستند. بیا یک نگاهی بیندازیم.
مقاله پیشنهادی:
+ list: یک آرایه قابل تغییر پویا
لیست ها بخشی از زبان اصلی پایتون هستند. علیرغم نام آنها، لیست های پایتون به عنوان آرایه های پویا در پشت صحنه پیاده سازی می شوند.
این بدان معنی است که یک لیست اجازه می دهد تا عناصر اضافه یا حذف شوند، و لیست به طور خودکار ذخیره پشتیبان که این عناصر را با اختصاص یا آزاد کردن حافظه تنظیم می کند، تنظیم می کند.
لیست های پایتون می توانند عناصر دلخواه را در خود جای دهند—همه چیز در پایتون یک شی است، از جمله توابع. بنابراین، می توانید انواع مختلفی از انواع داده ها را ترکیب و مطابقت دهید و همه آنها را در یک لیست واحد ذخیره کنید.
این می تواند یک ویژگی قدرتمند باشد، اما نقطه ضعف این است که پشتیبانی از چندین نوع داده به طور همزمان به این معنی است که داده ها به طور کلی کمتر فشرده هستند. در نتیجه کل ساختار فضای بیشتری را اشغال می کند:
>>> arr = [one, two, three]
>>> arr[0]
‘one’
>>> # Lists have a nice repr:
>>> arr
[‘one’, ‘two’, ‘three’]
>>> # Lists are mutable:
>>> arr[1] = hello
>>> arr
[‘one’, ‘hello’, ‘three’]
>>> del arr[1]
>>> arr
[‘one’, ‘three’]
>>> # Lists can hold arbitrary data types:
>>> arr.append(23)
>>> arr
[‘one’, ‘three’, 23]
ویدیو مرتبط:
+ tuple: کانتینرهای تغییر ناپذیر
درست مانند لیست ها، تاپل ها بخشی از زبان اصلی پایتون هستند. با این حال، بر خلاف لیست ها، اشیاء تاپل پایتون تغییرناپذیر هستند. این بدان معنی است که عناصر را نمی توان به صورت پویا اضافه یا حذف کرد – همه عناصر یک تاپل باید در زمان ایجاد تعریف شوند.
تاپل ها ساختار داده دیگری هستند که می توانند عناصری از انواع داده دلخواه را در خود جای دهند. داشتن این انعطاف پذیری قدرتمند است، اما باز هم به این معنی است که داده ها نسبت به آرایه های تایپی فشرده تر هستند:
>>> arr = (one, two, three)
>>> arr[0]
‘one’
>>> # Tuples have a nice repr:
>>> arr
(‘one’, ‘two’, ‘three’)
>>> # Tuples are immutable:
>>> arr[1] = hello
Traceback (most recent call last):
File , line 1, in
TypeError: ‘tuple’ object does not support item assignment
>>> del arr[1]
Traceback (most recent call last):
File , line 1, in
TypeError: ‘tuple’ object doesn’t support item deletion
>>> # Tuples can hold arbitrary data types:
>>> # (Adding elements creates a copy of the tuple)
>>> arr + (23,)
(‘one’, ‘two’, ‘three’, 23)
همچنین، آرایه ها از بسیاری از متدهای مشابه لیست های معمولی پشتیبانی می کنند و ممکن است بتوانید از آنها به عنوان جایگزینی کشویی بدون نیاز به تغییرات دیگری در کد برنامه خود استفاده کنید.
>>> import array
>>> arr = array.array(f, (1.0, 1.5, 2.0, 2.5))
>>> arr[1]
1.5
>>> # Arrays have a nice repr:
>>> arr
array(‘f’, [1.0, 1.5, 2.0, 2.5])
>>> # Arrays are mutable:
>>> arr[1] = 23.0
>>> arr
array(‘f’, [1.0, 23.0, 2.0, 2.5])
>>> del arr[1]
>>> arr
array(‘f’, [1.0, 2.0, 2.5])
>>> arr.append(42.0)
>>> arr
array(‘f’, [1.0, 2.0, 2.5, 42.0])
>>> # Arrays are typed:
>>> arr[1] = hello
Traceback (most recent call last):
File , line 1, in
TypeError: must be real number, not str
ویدیو مرتبط:
+ str: آرایه ای تغییر ناپذیر از کاراکترهای یونیکد
پایتون 3.x از اشیاء str برای ذخیره داده های متنی به عنوان دنباله های تغییرناپذیر کاراکترهای یونیکد استفاده می کند. از نظر عملی، این بدان معناست که یک str آرایه ای غیرقابل تغییر از کاراکترها است. به اندازه کافی عجیب، همچنین یک ساختار داده بازگشتی است – هر کاراکتر در یک رشته، خود یک شی str به طول 1 است.
اشیاء رشته ای در فضا کارآمد هستند، زیرا آنها کاملاً بسته بندی شده اند و در یک نوع داده واحد تخصص دارند. اگر متن یونیکد را ذخیره می کنید، باید از یک رشته استفاده کنید.
از آنجایی که رشته ها در پایتون تغییر ناپذیر هستند، تغییر رشته مستلزم ایجاد یک کپی تغییر یافته است. نزدیکترین معادل به یک رشته قابل تغییر، ذخیره کاراکترهای جداگانه در یک لیست است:
>>> arr = abcd
>>> arr[1]
‘b’
>>> arr
‘abcd’
>>> # Strings are immutable:
>>> arr[1] = e
Traceback (most recent call last):
File , line 1, in
TypeError: ‘str’ object does not support item assignment
>>> del arr[1]
Traceback (most recent call last):
File , line 1, in
TypeError: ‘str’ object doesn’t support item deletion
>>> # Strings can be unpacked into a list to
>>> # get a mutable representation:
>>> list(abcd)
[‘a’, ‘b’, ‘c’, ‘d’]
>>> .join(list(abcd))
‘abcd’
>>> # Strings are recursive data structures:
>>> type(abc)
>>> type(abc[0])
+ bytes: آرایه ای تغییر ناپذیر از یک بایت
اشیاء بایت دنباله های تغییرناپذیر بایت های منفرد یا اعداد صحیح در محدوده 0 تا 255 هستند.
مانند رشته ها، بایت ها نحو تحت اللفظی خود را برای ایجاد اشیاء دارند و در فضا کارآمد هستند. اشیاء بایت تغییرناپذیر هستند، اما برخلاف رشته ها، یک نوع داده آرایه بایت قابل تغییر اختصاصی وجود دارد که بایت آرایه نامیده می شود که می توان آن ها را در آن باز کرد:
>>> arr = bytes((0, 1, 2, 3))
>>> arr[1]
1
>>> # Bytes literals have their own syntax:
>>> arr
b’x00x01x02x03′
>>> arr = bx00x01x02x03
>>> # Only valid `bytes` are allowed:
>>> bytes((0, 300))
Traceback (most recent call last):
File , line 1, in
ValueError: bytes must be in range(0, 256)
>>> # Bytes are immutable:
>>> arr[1] = 23
Traceback (most recent call last):
File , line 1, in
TypeError: ‘bytes’ object does not support item assignment
>>> del arr[1]
Traceback (most recent call last):
File , line 1, in
TypeError: ‘bytes’ object doesn’t support item deletion
دوره پیشنهادی:
>>> arr = bytearray((0, 1, 2, 3))
>>> arr[1]
1
>>> # The bytearray repr:
>>> arr
bytearray(b’x00x01x02x03′)
>>> # Bytearrays are mutable:
>>> arr[1] = 23
>>> arr
bytearray(b’x00x17x02x03′)
>>> arr[1]
23
>>> # Bytearrays can grow and shrink in size:
>>> del arr[1]
>>> arr
bytearray(b’x00x02x03′)
>>> arr.append(42)
>>> arr
bytearray(b’x00x02x03*’)
>>> # Bytearrays can only hold `bytes`
>>> # (integers in the range 0 <=>>> arr[1] = hello
Traceback (most recent call last):
File , line 1, in
TypeError: ‘str’ object cannot be interpreted as an integer
>>> arr[1] = 300
Traceback (most recent call last):
File , line 1, in
ValueError: byte must be in range(0, 256)
>>> # Bytearrays can be converted back into bytes objects:
>>> # (This will copy the data)
>>> bytes(arr)
b’x00x02x03*’
دوره پیشنهادی:
+ نتیجه گیری: آرایه در پایتون
تعدادی ساختار داده داخلی وجود دارد که می توانید هنگام پیاده سازی آرایه ها در پایتون یکی از آنها را انتخاب کنید. در این بخش، شما بر ویژگی های زبان اصلی و ساختارهای داده موجود در کتابخانه استاندارد تمرکز کرده اید.
اگر می خواهید خود را به ساختارهای داده آرایه موجود در پایتون محدود کنید، در اینجا چند دستورالعمل وجود دارد:
- اگر نیاز به ذخیره اشیاء دلخواه، به طور بالقوه با انواع داده های مختلط دارید، بسته به اینکه ساختار داده غیرقابل تغییری می خواهید یا نه، از یک لیست یا یک تاپل استفاده کنید.
- اگر داده های عددی (اعداد صحیح یا ممیز اعشاری) دارید و بسته بندی و عملکرد بسیار مهم است، array.array را امتحان کنید.
- اگر داده های متنی دارید که به صورت کاراکترهای یونیکد نمایش داده می شوند، از str داخلی پایتون استفاده کنید. اگر به یک ساختار داده رشته مانند نیاز دارید، از list کاراکترها استفاده کنید.
- اگر می خواهید یک بلوک به هم پیوسته از بایت ها را ذخیره کنید از bytes استفاده کنید، اگر به ساختار داده ای قابل تغییر نیاز دارید، از نوع بایت های تغییرناپذیر یا bytearray استفاده کنید.
در بیشتر موارد، من دوست دارم با یک لیست ساده شروع کنم. فقط در صورتی که عملکرد یا فضای ذخیره سازی مشکلی ایجاد شود، بعداً نوع داده را تغییر میدهم. در بیشتر مواقع، استفاده از یک ساختار داده آرایه همه منظوره مانند لیست، سریع ترین راه توسعه و بیشترین راحتی برنامه نویسی را به شما می دهد.
# رکوردها، ساختارها و آبجکت های انتقال داده
در مقایسه با آرایه ها، ساختارهای داده رکورد(record) تعداد ثابتی از فیلدها را ارائه می دهند. هر فیلد می تواند یک نام داشته باشد و همچنین ممکن است نوع متفاوتی داشته باشد.
در این بخش، نحوه پیاده سازی رکوردها، ساختارها(struct) و اشیاء داده قدیمی را در پایتون با استفاده از انواع داده های داخلی و کلاس های کتابخانه استاندارد خواهید دید.
ویدیو مرتبط:
+ dict: نوع داده ساده
استفاده از دیکشنری ها به عنوان یک نوع داده رکورد یا شی داده در پایتون امکان پذیر است. ایجاد دیکشنری در پایتون آسان است، زیرا آنها سینتکس خاص خود را در زبان دارند. نحو دیکشنری مختصر و برای تایپ بسیار راحت است.
اشیاء داده ایجاد شده با استفاده از دیکشنری قابل تغییر هستند و محافظت کمی در برابر نام فیلدهای غلط املایی وجود دارد زیرا فیلدها می توانند آزادانه در هر زمان اضافه و حذف شوند. هر دوی این ویژگی ها می توانند باگ های شگفت انگیزی را ایجاد کنند، و همیشه بین راحتی و انعطاف پذیری خطا، معاوضه ای وجود دارد:
>>> car1 = {
… color: red,
… mileage: 3812.4,
… automatic: True,
… }
>>> car2 = {
… color: blue,
… mileage: 40231,
… automatic: False,
… }
>>> # Dicts have a nice repr:
>>> car2
{‘color’: ‘blue’, ‘automatic’: False, ‘mileage’: 40231}
>>> # Get mileage:
>>> car2[mileage]
40231
>>> # Dicts are mutable:
>>> car2[mileage] = 12
>>> car2[windshield] = broken
>>> car2
{‘windshield’: ‘broken’, ‘color’: ‘blue’,
‘automatic’: False, ‘mileage’: 12}
>>> # No protection against wrong field names,
>>> # or missing/extra fields:
>>> car3 = {
… colr: green,
… automatic: False,
… windshield: broken,
… }
ویدیو مرتبط:
+ tuple: یک گروه تغییرناپذیر از آبجکت ها
تاپل های پایتون یک ساختار داده ساده برای گروه بندی اشیاء دلخواه هستند. تاپل ها تغییر ناپذیر هستند – پس از ایجاد نمی توان آنها را تغییر داد.
از نظر عملکرد، تاپل ها نسبت به لیست های موجود در CPython کمی حافظه کمتری اشغال می کنند، و همچنین سریعتر ساخته می شوند.
>>> import dis
>>> dis.dis(compile((23, ‘a’, ‘b’, ‘c’), , eval))
0 LOAD_CONST 4 ((23, a, b, c))
3 RETURN_VALUE
>>> dis.dis(compile([23, ‘a’, ‘b’, ‘c’], , eval))
0 LOAD_CONST 0 (23)
3 LOAD_CONST 1 (‘a’)
6 LOAD_CONST 2 (‘b’)
9 LOAD_CONST 3 (‘c’)
12 BUILD_LIST 4
15 RETURN_VALUE
با این حال، شما نباید روی این تفاوت ها تاکید زیادی داشته باشید. در عمل، تفاوت عملکرد اغلب ناچیز خواهد بود، و تلاش برای حذف عملکرد اضافی از یک برنامه با تغییر از لیست به تاپل، احتمالاً رویکرد اشتباهی خواهد بود.
یک نقطه ضعف بالقوه تاپل های ساده این است که داده هایی که در آنها ذخیره می کنید تنها با دسترسی به آنها از طریق ایندکس های اعداد صحیح قابل استخراج است. شما نمی توانید نامی برای خصوصیات فردی که در یک تاپل ذخیره شده اند بدهید. این می تواند بر خوانایی کد تأثیر بگذارد.
این باعث می شود که به راحتی بتوان باگ های اشتباه را معرفی کرد، مانند اختلاط ترتیب میدانی. بنابراین، توصیه می کنم تعداد فیلدهای ذخیره شده در یک تاپل را تا حد امکان کم نگه دارید:
>>> # Fields: color, mileage, automatic
>>> car1 = (red, 3812.4, True)
>>> car2 = (blue, 40231.0, False)
>>> # Tuple instances have a nice repr:
>>> car1
(‘red’, 3812.4, True)
>>> car2
(‘blue’, 40231.0, False)
>>> # Get mileage:
>>> car2[1]
40231.0
>>> # Tuples are immutable:
>>> car2[1] = 12
Traceback (most recent call last):
File , line 1, in
TypeError: ‘tuple’ object does not support item assignment
>>> # No protection against missing or extra fields
>>> # or a wrong order:
>>> car3 = (3431.5, green, True, silver)
ویدیو پیشنهادی:
+ ساخت کلاس سفارشی: کار بیشتر، کنترل بیشتر
کلاس ها به شما امکان می دهند طرح های قابل استفاده مجدد را برای اشیاء داده تعریف کنید تا اطمینان حاصل کنید که هر شی مجموعه ای از فیلدها را ارائه می دهد.
استفاده از کلاس های پایتون معمولی به عنوان انواع داده های رکورد امکان پذیر است، اما برای دستیابی به ویژگی های راحتی سایر پیاده سازی ها نیز به کار دستی نیاز است. به عنوان مثال، افزودن فیلدهای جدید به سازنده __init__ پیچیده است و زمان می برد.
همچنین، نمایش رشته پیش فرض برای اشیاء نمونه سازی شده از کلاس های سفارشی چندان مفید نیست. برای رفع آن، ممکن است مجبور شوید متد خود را اضافه کنید، که معمولاً کاملاً پرمخاطب است و باید هر بار که یک فیلد جدید اضافه می کنید، به روزرسانی شود.
فیلدهای ذخیره شده در کلاس ها قابل تغییر هستند و فیلدهای جدید را می توان آزادانه اضافه کرد که ممکن است دوست داشته باشید یا نخواهید. امکان کنترل دسترسی بیشتر و ایجاد فیلدهای فقط خواندنی با استفاده از دکوراتور وجود دارد، اما یک بار دیگر، این نیاز به نوشتن کد چسب بیشتری دارد.
هر زمان که بخواهید منطق و رفتار تجاری را با استفاده از متدها به اشیاء رکورد خود اضافه کنید، نوشتن یک کلاس سفارشی یک گزینه عالی است. با این حال، این بدان معنی است که این اشیاء از نظر فنی دیگر اشیاء داده ساده نیستند:
>>> class Car:
… def __init__(self, color, mileage, automatic):
… self.color = color
… self.mileage = mileage
… self.automatic = automatic
…
>>> car1 = Car(red, 3812.4, True)
>>> car2 = Car(blue, 40231.0, False)
>>> # Get the mileage:
>>> car2.mileage
40231.0
>>> # Classes are mutable:
>>> car2.mileage = 12
>>> car2.windshield = broken
>>> # String representation is not very useful
>>> # (must add a manually written __repr__ method):
>>> car1
کلاس های داده در پایتون 3.7 و بالاتر در دسترس هستند. آنها یک جایگزین عالی برای تعریف کلاس های ذخیره سازی داده های خود از ابتدا ارائه می دهند.
- سینتکس برای تعریف متغیرهای instance کوتاهتر است، زیرا نیازی به پیاده سازی متد .__init__() ندارید.
- instanceهایی که از data calssهای شما ساخته میشوند به طور خودکار از طریق یک متد .__repr__() که به طور خودکار تولید می شود، نمایش رشته ای با ظاهر زیبا دریافت می کنند.
- Instance variableها type annotations را می پذیرند و dataclassهای شما را تا حدی مستند می کنند. به خاطر داشته باشید که type annotationsها فقط نکاتی هستند که بدون ابزار بررسی نوع جداگانه اعمال نمی شوند.
>>> from dataclasses import dataclass
>>> @dataclass
… class Car:
… color: str
… mileage: float
… automatic: bool
…
>>> car1 = Car(red, 3812.4, True)
>>> # Instances have a nice repr:
>>> car1
Car(color=’red’, mileage=3812.4, automatic=True)
>>> # Accessing fields:
>>> car1.mileage
3812.4
>>> # Fields are mutable:
>>> car1.mileage = 12
>>> car1.windshield = broken
>>> # Type annotations are not enforced without
>>> # a separate type checking tool like mypy:
>>> Car(red, NOT_A_FLOAT, 99)
Car(color=’red’, mileage=’NOT_A_FLOAT’, automatic=99)
ویدیو پیشنهادی:
علاوه بر این، اشیاء نامگذاری شده، خوب هستند. . . تاپل ها به نام هر شی ذخیره شده در آنها از طریق یک شناسه منحصر به فرد قابل دسترسی است. این شما را از به خاطر سپردن شاخص های اعداد صحیح یا متوسل شدن به راه حل هایی مانند تعریف ثابت های عدد صحیح به عنوان یادگاری برای ایندکس های خود رها می کند.
>>> from collections import namedtuple
>>> from sys import getsizeof
>>> p1 = namedtuple(Point, x y z)(1, 2, 3)
>>> p2 = (1, 2, 3)
>>> getsizeof(p1)
64
>>> getsizeof(p2)
64
استفاده از اشیاء نام گذاری شده روی تاپل ها و dictهای معمولی(بدون ساختار) همچنین می تواند زندگی همکاران شما را با ایجاد داده هایی که در اطراف خود مستندسازی می شوند، حداقل تا حدی آسان تر کند:
>>> from collections import namedtuple
>>> Car = namedtuple(Car , color mileage automatic)
>>> car1 = Car(red, 3812.4, True)
>>> # Instances have a nice repr:
>>> car1
Car(color=red, mileage=3812.4, automatic=True)
>>> # Accessing fields:
>>> car1.mileage
3812.4
>>> # Fields are immtuable:
>>> car1.mileage = 12
Traceback (most recent call last):
File , line 1, in
AttributeError: can’t set attribute
>>> car1.windshield = broken
Traceback (most recent call last):
File , line 1, in
AttributeError: ‘Car’ object has no attribute ‘windshield’
ویدیو پیشنهادی:
>>> from typing import NamedTuple
>>> class Car(NamedTuple):
… color: str
… mileage: float
… automatic: bool
>>> car1 = Car(red, 3812.4, True)
>>> # Instances have a nice repr:
>>> car1
Car(color=’red’, mileage=3812.4, automatic=True)
>>> # Accessing fields:
>>> car1.mileage
3812.4
>>> # Fields are immutable:
>>> car1.mileage = 12
Traceback (most recent call last):
File , line 1, in
AttributeError: can’t set attribute
>>> car1.windshield = broken
Traceback (most recent call last):
File , line 1, in
AttributeError: ‘Car’ object has no attribute ‘windshield’
>>> # Type annotations are not enforced without
>>> # a separate type checking tool like mypy:
>>> Car(red, NOT_A_FLOAT, 99)
Car(color=’red’, mileage=’NOT_A_FLOAT’, automatic=99)
+ struct.Struct: ساختار های سریالایز C
کلاس struct.Struct بین مقادیر پایتون و ساختارهای C سریال شده به اشیاء بایت پایتون تبدیل می کند. به عنوان مثال، می توان از آن برای مدیریت داده های باینری ذخیره شده در فایل ها یا دریافت از اتصالات شبکه استفاده کرد.
structهای سریالایز شده به ندرت برای نشان دادن اشیاء داده استفاده می شوند که صرفاً در کد پایتون مدیریت می شوند. آنها در درجه اول به عنوان یک قالب تبادل داده در نظر گرفته شده اند تا به عنوان راهی برای نگهداری داده ها در حافظه که فقط توسط کد پایتون استفاده می شود.
در برخی موارد، بسته بندی داده های اولیه در ساختارها ممکن است از حافظه کمتری نسبت به نگهداری آن در سایر انواع داده استفاده کند. با این حال، در بیشتر موارد این یک بهینه سازی کاملاً پیشرفته (و احتمالاً غیر ضروری) خواهد بود:
>>> from struct import Struct
>>> MyStruct = Struct(i?f)
>>> data = MyStruct.pack(23, False, 42.0)
>>> # All you get is a blob of data:
>>> data
b’x17x00x00x00x00x00x00x00x00x00(B’
>>> # Data blobs can be unpacked again:
>>> MyStruct.unpack(data)
(23, False, 42.0)
ویدیو پیشنهادی:
>>> from types import SimpleNamespace
>>> car1 = SimpleNamespace(color=red, mileage=3812.4, automatic=True)
>>> # The default repr:
>>> car1
namespace(automatic=True, color=’red’, mileage=3812.4)
>>> # Instances support attribute access and are mutable:
>>> car1.mileage = 12
>>> car1.windshield = broken
>>> del car1.automatic
>>> car1
namespace(color=’red’, mileage=12, windshield=’broken’)
+ نتیجه گیری: رکوردها، ساختار ها و آبجکت های انتقال داده
همانطور که مشاهده کردید، تعداد زیادی گزینه مختلف برای اجرای رکوردها یا اشیاء داده وجود دارد. از کدام نوع برای اشیاء داده در پایتون استفاده کنید؟ به طور کلی تصمیم شما به مورد استفاده شما بستگی دارد:
- اگر فقط چند فیلد دارید، در صورتی که ترتیب فیلدها به راحتی قابل یادآوری باشد یا نام فیلدها اضافی باشد، استفاده از یک شی تاپلی ساده ممکن است مشکلی نداشته باشد. به عنوان مثال، به یک نقطه (x، y، z) در فضای سه بعدی فکر کنید.
- اگر به فیلدهای تغییرناپذیر نیاز دارید، پس تاپل های ساده، collections.namedtuple و typing.NamedTuple همگی گزینه های خوبی هستند.
- اگر باید نام فیلدها را قفل کنید تا از اشتباهات املایی جلوگیری شود، collections.namedtuple و typing.NamedTuple دوستان شما هستند.
- اگر می خواهید همه چیز را ساده نگه دارید، یک شیء دیکشنری ساده ممکن است به دلیل نحو مناسبی که بسیار شبیه JSON است، انتخاب خوبی باشد.
- اگر به کنترل کامل بر روی ساختار داده خود نیاز دارید، زمان آن رسیده است که یک کلاس سفارشی با تنظیم کننده ها و دریافت کننده های property@ بنویسید.
- اگر برای سریال سازی آن ها روی دیسک یا ارسال آن ها از طریق شبکه نیاز به بسته بندی محکم دارید، وقت آن است که struct.Struct را بخوانید زیرا این یک مورد استفاده عالی برای آن است!
ویدیو پیشنهادی:
# set و multiset
در این بخش، نحوه پیاده سازی ساختارهای داده قابل تغییر و تغییرناپذیر set و multiset را در پایتون با استفاده از انواع داده ها و کلاس های داخلی کتابخانه استاندارد خواهید دید.
set مجموعه ای نامرتب از اشیاء است که اجازه تکرار عناصر را نمی دهد. به طور معمول، setها برای آزمایش سریع یک مقدار برای عضویت در مجموعه، برای درج یا حذف مقادیر جدید از یک مجموعه، و برای محاسبه اتحاد(union) یا تقاطع(intersection) دو مجموعه استفاده می شوند.
در اجرای set مناسب، انتظار می رود که آزمون های عضویت در زمان O(1) سریع اجرا شوند. عملیات اتحاد، تقاطع، تفاوت و زیر مجموعه باید به طور متوسط زمان O(n) داشته باشد. set پیاده سازی شده موجود در کتابخانه استاندارد پایتون از این ویژگی های عملکرد پیروی می کنند.
درست مانند دیکشنری ها، setها در پایتون مورد توجه ویژه قرار می گیرند و ساختن آنها آسان است.
vowels = {a, e, i, o, u}
squares = {x * x for x in range(10)}
اما مراقب باشید: برای ایجاد یک set خالی، باید متد set() را فراخوانی کنید. استفاده از آکولاد خالی ({}) مبهم است و به جای آن یک دیکشنری خالی ایجاد می کند.
پایتون و کتابخانه استاندارد آن چندین set پیاده سازی را ارائه می دهند. بیایید نگاهی به آنها بیندازیم.
+ set: مجموعه در دسترس شما
نوع set، اجرای مجموعه داخلی در پایتون است. قابل تغییر است و امکان درج و حذف پویا عناصر را فراهم می کند.
setهای پایتون توسط نوع داده dict پشتیبانی می شوند و ویژگی های عملکردی یکسانی دارند. هر شیء قابل هش را می توان در set ذخیره کرد:
>>> vowels = {a, e, i, o, u}
>>> e in vowels
True
>>> letters = set(alice)
>>> letters.intersection(vowels)
{‘a’, ‘e’, ‘i’}
>>> vowels.add(x)
>>> vowels
{‘i’, ‘a’, ‘u’, ‘o’, ‘x’, ‘e’}
>>> len(vowels)
6
+ frozenset: نوع set تغییرناپذیز
کلاس frozenset یک نسخه تغییرناپذیر از set را پیاده سازی می کند که پس از ساخته شدن قابل تغییر نیست.
اشیای frozenset ثابت هستند و فقط عملیات پرس و جو را روی عناصر خود اجازه می دهند، نه درج یا حذف. از آنجا که اشیاء frozenset ثابت و قابل هش هستند، می توانند به عنوان کلیدهای دیکشنری یا عناصر set دیگری استفاده شوند، چیزی که با اشیاء set معمولی (تغییرپذیر) امکان پذیر نیست:
>>> vowels = frozenset({a, e, i, o, u})
>>> vowels.add(p)
Traceback (most recent call last):
File , line 1, in
AttributeError: ‘frozenset’ object has no attribute ‘add’
>>> # Frozensets are hashable and can
>>> # be used as dictionary keys:
>>> d = { frozenset({1, 2, 3}): hello }
>>> d[frozenset({1, 2, 3})]
‘hello’
+ collections.Counter: چند set
در کتابخانه استاندارد پایتون یک نوع multiset را پیاده سازی می کند که به عناصر set اجازه می دهد بیش از یک رخداد داشته باشند.
این در صورتی مفید است که لازم است نه تنها یک عنصر بخشی از یک مجموعه را ردیابی کنید، بلکه چند بار در مجموعه گنجانده شده است:
>>> from collections import Counter
>>> inventory = Counter()
>>> loot = {sword: 1, bread: 3}
>>> inventory.update(loot)
>>> inventory
Counter({‘bread’: 3, ‘sword’: 1})
>>> more_loot = {sword: 1, apple: 1}
>>> inventory.update(more_loot)
>>> inventory
Counter({‘bread’: 3, ‘sword’: 2, ‘apple’: 1})
یک نکته برای کلاس Counter این است که باید هنگام شمارش تعداد عناصر موجود در یک شی Counter مراقب باشید. فراخوانی len() تعداد عناصر منحصر به فرد را در multiset برمی گرداند، در حالی که تعداد کل عناصر را می توان با استفاده از sum() به دست آورد:
>>> len(inventory)
3 # Unique elements
>>> sum(inventory.values())
6 # Total no. of elements
از نظر عملکرد، انتظار می رود اجرای پشته مناسب برای عملیات درج و حذف زمان O(1) را ببرد.
+ list: ساده و داخلی
نوع لیست داخلی پایتون یک ساختار داده پشته مناسبی ایجاد می کند زیرا از عملیات push و pop در زمان استهلاک O(1) پشتیبانی می کند.
فهرست های پایتون به عنوان آرایه های پویا در داخل پیاده سازی می شوند، به این معنی که گهگاه نیاز به تغییر اندازه فضای ذخیره سازی عناصر ذخیره شده در آنها هنگام افزودن یا حذف عناصر دارند. list، فضای ذخیره سازی پشتیبان خود را بیش از حد اختصاص می دهد، به طوری که هر push یا pop نیازی به تغییر اندازه ندارد. در نتیجه، پیچیدگی زمانی O(1) مستهلک شده برای این عملیات دریافت می کنید.
افزودن و حذف از جلو بسیار کندتر است و زمان O(n) را می طلبد، زیرا عناصر موجود باید به اطراف جابجا شوند تا فضا برای عنصر جدید باز شود. این یک ضد الگوی عملکرد است که باید تا حد امکان از آن اجتناب کنید:
>>> s = []
>>> s.append(eat)
>>> s.append(sleep)
>>> s.append(code)
>>> s
[‘eat’, ‘sleep’, ‘code’]
>>> s.pop()
‘code’
>>> s.pop()
‘sleep’
>>> s.pop()
‘eat’
>>> s.pop()
Traceback (most recent call last):
File , line 1, in
IndexError: pop from empty list
+ collections.deque: سریع و قوی
>>> from collections import deque
>>> s = deque()
>>> s.append(eat)
>>> s.append(sleep)
>>> s.append(code)
>>> s
deque([‘eat’, ‘sleep’, ‘code’])
>>> s.pop()
‘code’
>>> s.pop()
‘sleep’
>>> s.pop()
‘eat’
>>> s.pop()
Traceback (most recent call last):
File , line 1, in
IndexError: pop from an empty deque
# Queue(FIFO)
در این بخش، نحوه پیاده سازی ساختار داده صف First-In/First-Out (FIFO) را با استفاده از انواع داده های داخلی و کلاس های کتابخانه استاندارد پایتون خواهید دید.
صف مجموعه ای از اشیاء است که از معنای سریع FIFO برای درج و حذف پشتیبانی می کند. عملیات درج و حذف را گاهی اوقات enqueue و dequeue می نامند. برخلاف listها یا آرایه ها، صف ها معمولاً اجازه دسترسی تصادفی به اشیاء موجود در آنها را نمی دهند.
از نظر عملکرد، انتظار می رود که اجرای صف مناسب، زمان O(1) را برای عملیات درج و حذف ببرد. این دو عملیات اصلی هستند که روی یک صف انجام می شوند و در اجرای صحیح باید سریع باشند.
+ list: یک صف بسیار کند
استفاده از یک لیست معمولی به عنوان صف امکان پذیر است، اما این از منظر عملکرد ایده آل نیست. لیست ها برای این منظور بسیار کند هستند زیرا درج یا حذف یک عنصر در ابتدا مستلزم جابجایی تمام عناصر دیگر به اندازه یک ایندکس، به زمان O(n) است.
بنابراین، من استفاده از یک لیست را به عنوان یک صف موقت در پایتون توصیه نمی کنم، مگر اینکه فقط با تعداد کمی از عناصر سروکار داشته باشید:
>>> q = []
>>> q.append(eat)
>>> q.append(sleep)
>>> q.append(code)
>>> q
[‘eat’, ‘sleep’, ‘code’]
>>> # Careful: This is slow!
>>> q.pop(0)
‘eat’
+ collections.deque: صف سریع و قوی
در نتیجه، اگر به دنبال ساختار داده صف در کتابخانه استاندارد پایتون هستید، collections.deque یک انتخاب پیش فرض عالی است:
>>> from collections import deque
>>> q = deque()
>>> q.append(eat)
>>> q.append(sleep)
>>> q.append(code)
>>> q
deque([‘eat’, ‘sleep’, ‘code’])
>>> q.popleft()
‘eat’
>>> q.popleft()
‘sleep’
>>> q.popleft()
‘code’
>>> q.popleft()
Traceback (most recent call last):
File , line 1, in
IndexError: pop from an empty deque
+ Queue.queue: قفل کردن برای محاسبات موازی
اجرای queue.Queue در کتابخانه استاندارد پایتون همزمان است و قفل را برای پشتیبانی از چندین تولید کننده(producers) و مصرف کننده(consumers) همزمان ارائه می دهد.
ماژول queue شامل چندین کلاس دیگر است که صف های چند تولید کننده و چند مصرف کننده را پیاده سازی می کنند که برای محاسبات موازی مفید هستند.
بسته به مورد استفاده شما، قفل ممکن است مفید باشد یا فقط هزینه های غیر ضروری را متحمل شود. در این مورد، بهتر است از collections.deque به عنوان یک صف همه منظوره استفاده کنید:
>>> from queue import Queue
>>> q = Queue()
>>> q.put(eat)
>>> q.put(sleep)
>>> q.put(code)
>>> q
>>> q.get()
‘eat’
>>> q.get()
‘sleep’
>>> q.get()
‘code’
>>> q.get_nowait()
queue.Empty
>>> q.get() # Blocks/waits forever…
# نتیجه گیری
به این ترتیب گشت و گذار شما در ساختارهای داده رایج در پایتون به پایان می رسد. با دانشی که در اینجا به دست آورده اید، آماده اجرای ساختارهای داده کارآمدی هستید که برای الگوریتم خاص یا مورد استفاده شما مناسب هستند.
بهترین آموزشگاه پایتون در اصفهان با آموزش کامل پایتون به صورت آنلاین و حضوری آماده ارائه خدمات به شما عزیزان می باشد